Czym jest fault tolerance?
Chociaż historia systemów rozproszonych sięga dużo dalej w przeszłość, szerszą popularność zdobyły wraz z popularyzacją Bitcoina opartego na sieci Blockchain. Blockchain został zaprojektowany jako sieć niewymagająca scentralizowanego serwera, przez co jej uczestnicy muszą uzgadniać stan całej sieci między sobą, a sieć zapisuje wszystkie te decyzje w swoim “rejestrze”, do którego każdy uczestnik ma dostęp.
Jednym z fundamentalnych problemów systemów rozproszonych jest podjęcie wspólnej decyzji przez wszystkie węzły w przypadku, gdy niektóre z nich zachowują się nieprawidłowo. Powody nieprawidłowego działania są różnorakie, może to być odcięcie od sieci przez awarię, przejęcie danego węzła przez hackerów czy po prostu błąd w kodzie.
Mechanizmy decentralizacji na poziomie całych systemów jak i pojedynczych komponentów wykorzystuje się również w branżach takich jak np. lotnictwo, energetyka i branża kosmiczna.

W przypadku sieci informatycznych awaria członka sieci może skutkować np. niedostarczeniem wiadomości do adresata czy brakiem dostępu do danych. W systemach wykorzystywanych przemysłowo stawka jest dużo wyższa.
Wyobraźmy sobie wartą setki milionów dolarów rakietę, która może niekontrolowanie zmienić kurs czy ustawienia silnika przez awarię jednego z modułów kontroli lotu – byłoby to bardzo ryzykowne, dlatego normą jest montaż kilku takich urządzeń działających niezależnie od siebie i komunikujących się w momencie podjęcia decyzji o zmianie parametrów lotu. Dzięki tej technice cały system jest mniej zawodny i odporny na awarię. Jeżeli jeden z modułów przestanie działać lub zadziała wadliwie, to zostanie to wykryte podczas weryfikacji decyzji z pozostałymi, poprawnie działającymi urządzeniami. Systemy posiadające zdolność do poprawnego działania w przypadku pojawienia się błędów i awarii ich części nazywamy odpornymi na awarię (ang. fault tolerant).
Co mają wspólnego średniowieczni generałowie ze współczesnymi systemami rozproszonymi?
Problem przedstawiony wyżej został konkretnie sformułowany w 1982r. przez grupę Microsoft Research w składzie Marshall Pease, Leslie Lamport oraz Robert Shostak.
Wyobraźmy sobie kilka dywizji bizantyjskiego wojska otaczających wrogie miasto. Na czele każdej dywizji stoi generał, który zadecyduje o ataku lub odwrocie podległej mu dywizji, a dywizje są rozlokowane w sporej odległości od siebie.
Generałowie muszą podjąć decyzję o ataku lub odwrocie, nie ma znaczenia którą z nich podejmą o ile każda dywizja zachowa się w ten sam sposób. Jeżeli nie zaatakują równocześnie, to ich siły polegną i miasto zdoła się obronić, a w przypadku gdy zdecydują o odwrocie, wojska przeżyją i mogą ponowić atak w przyszłości.
Generałowie komunikują się ze sobą przy pomocy zaufanych posłańców, którzy dostarczają wiadomości z decyzjami pomiędzy nimi.
Głównymi wyzwaniami przedstawionej sytuacji są:
- wiadomości wysłane przez posłańców mogą nie dotrzeć do celu lub dotrzeć do niego zbyt późno
- niektórzy z generałów mogą być zdrajcami, którym zależy na porażce sprzymierzonych z nimi wojsk
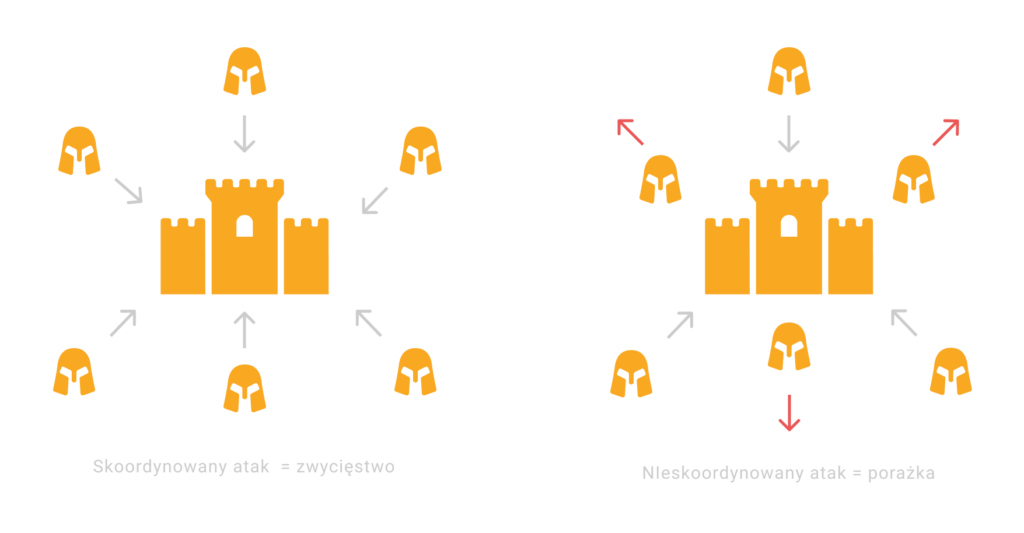
Atak w tym przypadku jest próbą przekonania uczciwych generałów przez zdrajców do podjęcia szkodliwej dla systemu decyzji.
Przykład:
- Generał A postanawia o odwrocie i wysłał swojego posłańca z decyzją
- Generał B jest zdrajcą i rozsyła wiadomości z decyzją o ataku, przez co może zmienić decyzje części generałów zdecydowanych na odwórt
- Generał A dostaje wiadomość od generała B, postanawia zaatakować i ponosi porażkę, ponieważ Generał B był zdrajcą, który nie zaatakował
Przyjrzyjmy się także przykładowi z oryginalnego opracowania twórców algorytmu, tutaj dochodzi nam jeszcze głównodowodzący generał, który podejmuje wstępną decyzję, a jego decyzję przekazują między sobą porucznicy.
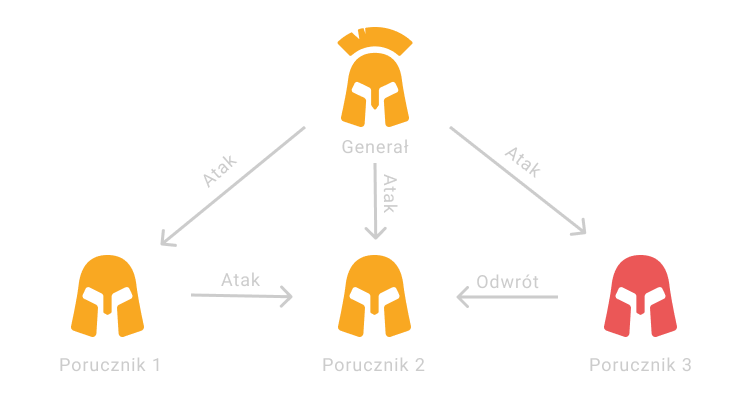
Przejdźmy teraz po kolei po krokach algorytmu:
- Generał rozsyła do poruczników swoją decyzję o ataku
- Porucznicy przekazują wiadomości od generała między sobą w celu ich potwierdzenia
- Porucznik 1 przesyła poprawną wiadomość do Porucznika 2
- Porucznik 3 (zdrajca) przesyła fałszywą wiadomość do porucznika 2
- Porucznik 2 podejmuje decyzję, która została mu wysłana przez większość uczestników, czyli decyzję o ataku
- Sieć osiąga konsensus dla wartości Atak, ponieważ większość jej członków się z nią zgodziła
Przekładając problem bizantyjskich generałów do sieci komputerowych – każdy z generałów jest węzłem w zdecentralizowanej sieci. Wszystkie węzły muszą podjąć wspólna decyzję o kolejnym stanie sieci (np. nowym bloku sieci Blockchain) w celu kontynuacji jej działania. Bez osiągnięcia konsensusu sieć jest sparaliżowana.
Odporność na problem bizantyjskich generałów
Odpornością na problem bizantyjskich generałów (Byzantine Fault Tolerance) nazywany cechę systemu, która potrafi oprzeć się bizantyjskiemu atakowi wynikającemu z rozproszonej natury sieci. Jeżeli któryś z węzłów zostanie uszkodzony lub zainfekowany, to cały system i tak będzie w stanie podjąć właściwą decyzję.
Ważnym założeniem jest brak założeń odnośnie oczekiwanego zachowania danych uczestników sieci – system nie podejrzewa nikogo o złośliwe zachowanie, tylko eliminuje jego skutki na etapie osiągania konsensusu.Z punktu widzenia rozproszonej sieci Blockchain, odporność na bizantyjskie wady jest jedną z kluczowych cech systemu. Najpopularniejszymi algorytmami konsensusu jest Proof of Work i Proof of Stake, które pozwalają się bronić przed atakami tego typu. Badania nad algorytmami BFT nabrały tempa wraz ze wzrostem popularności Blockchaina i kryptowalut, przez co możemy obserwować coraz bardziej efektywne metody radzenia sobie z tym dylematem.


